
Spark é um poderoso mecanismo de processamento de código aberto construído em torno de velocidade, facilidade de utilização, e análises sofisticadas. Ela foi originalmente desenvolvida na Universidade de Berkeley em 2009. O framework Spark é 100% open source, hospedado no Apache Software Foundation independente de fornecedor.
Potências da Internet como Netflix, Yahoo e eBay o implementaram em escala maciça, processar coletivamente múltiplos petabytes de dados em clusters de mais de 8.000 nós. Ele rapidamente se tornou a maior comunidade open source em dados grandes, com mais de 1000 colaboradores de mais de 250 organizações.
O projeto veio para resolver problemas de performance e processamento paralelo, criando assim um poderoso ambiente de execução em memória nunca visto anteriormente. Rapidamente adotado, se transformou em base para diversas aplicações como : BigData, Machine Learning, Streaming de Dados, SQL, além de processamento de Grafos entre outras
Juntamente com a comunidade, a Databricks continua a contribuir fortemente para o projeto Apache, tanto através do desenvolvimento e evangelismo comunidade.
“No Databricks, estamos trabalhando duro para fazer Spark mais fácil de usar e executar do que nunca, através de nossos esforços, tanto a base de código de ignição e materiais de apoio em torno dele. Todo o nosso trabalho é open source e vai diretamente para Apache “.
– Matei Zaharia, VP, Spark,
fundador e CTO, Databricks
Quais são os benefícios do Spark?
VELOCIDADE
Projetado a partir do bottom-up para o desempenho, ele pode ser 100x mais rápido do que o Hadoop para o processamento de dados em grande escala, explorando em computação memória e outras otimizações. Ele também é rápido quando os dados são armazenados no disco e atualmente detém o recorde mundial de grande escala de classificação no disco. A distribuição dos dados em memória e seu processamento paralelo tornam o framework muito performático para qualquer tipo de processamento.
FÁCIL DE USAR
O Projeto tem APIs fáceis de usar para operar em grandes conjuntos de dados. Isso inclui uma coleção de mais de 100 operadores para transformar APIs de dados e estrutura de dados familiar para manipulação de dados semi-estruturados. A possibilidade de integra-lo com diversas bibliotecas e linguaguens facilitam muito o dia a dia do desenvolvedor que pode utilizar linguagens como : Python, Scala, Java ou R.
A Opção de usar o SQL também torna muito mais fácil a programação das consultas e extrações de dados, visto que o SQL é a linguagem de consulta de dados mais comum em tecnologia, o Spark SQL abstrai a complexidade do bigdata tornando a consulta de dados de volumes gigantescos tão simples quanto escrever um SELECT para buscar dados de uma tabela de banco de dados relacionais e mais simples como MySql ou PostgreSql
AMPLA BIBLIOTECA
O Spark vem embalado com bibliotecas de nível superior, incluindo suporte para consultas SQL, streaming de dados, aprendizado de máquina e processamento gráfico. Essas bibliotecas padrão aumentar a produtividade do desenvolvedor e pode ser perfeitamente combinados para criar fluxos de trabalho complexos.
O projeto é Open Source, 100% gratuito. Você pode baixar através do site que também contém instruções de instalação, tutoriais em vídeo e documentação para você começar.
Spark Core
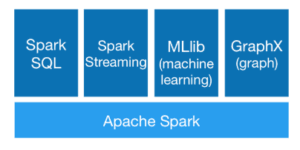
Consideramos Core a parte fundamental do software onde rodam os RDDs ( Resilient Distributed Datasets ) que são a parte fundamental da tecnologia de processamento distribuído, abaixo os módulos que rodam sobre o Core
- SQL – http://spark.apache.org/sql/
- Streaming – http://spark.apache.org/streaming/
- MLLib ( Machine Learning ) – http://spark.apache.org/mllib/
- GraphX (graph) – http://spark.apache.org/graphx/
Spark ou Hadoop
Talvez seja comum encontrar na internet essa comparação entre Spark ou Hadoop, qual usar ?
Não faz sentido comparar as 2 tecnologias, Hadoop é um framework de Armazenamento Distribuído baseado em HDFS ( Hadoop Distributed File System ) e Spark é um framework de processamento em Memória.
No Hadoop o processamento principal é feito pelo Map Reduce, que foi modernizado com a chegada do YARN no Hadoop 2, mas de qualquer maneira o Hadoop também pode usar Spark como processador de seus dados, substituindo em boa parte das funções o Map Reduce.
Então, na dúvida entre qual usar, use sempre os dois !
VEJA MAIS SOBRE HADOOP – https://www.cetax.com.br/apache-hadoop/

