ETL: O Processo de Extração, Transformação e Carga de Dados
Extraction, Transform and Load – ETL
1. Introdução ao ETL
ETL, que significa Extração, Transformação e Carga, é um processo fundamental no gerenciamento de dados em empresas de todos os portes. Ele se refere ao fluxo de trabalho que extrai dados de várias fontes, os transforma para atender a necessidades específicas e os carrega em um sistema de destino, como um Data Warehouse ou um Data Lake.
O ETL começou a ganhar força com o aumento do uso de data warehouses tradicionais, onde dados de várias fontes eram centralizados para serem usados em Business Intelligence (BI). No entanto, com a chegada do Big Data e das tecnologias modernas de processamento de dados, o ETL evoluiu para lidar com volumes e velocidades muito maiores. Hoje, ele desempenha um papel crucial na integração de dados e no suporte à tomada de decisões baseada em dados.
2. O Processo de ETL
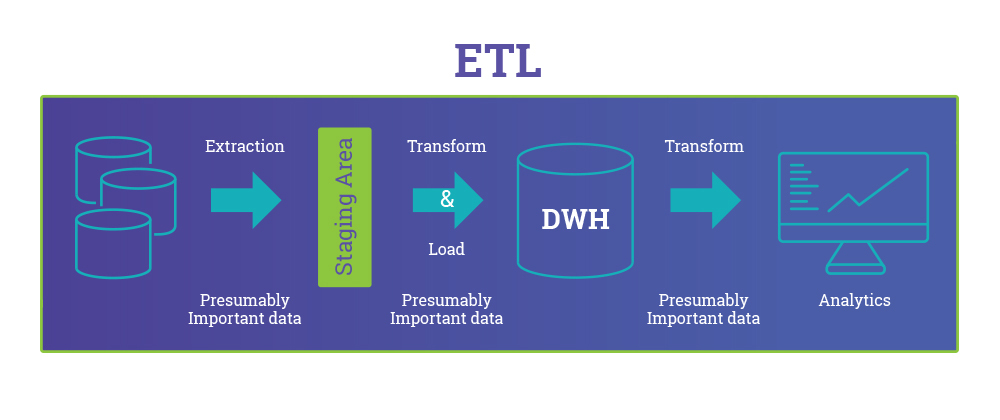
O fluxo de trabalho do ETL é dividido em três etapas principais:
- Extração: Nesta fase, os dados são coletados de diversas fontes, que podem incluir bancos de dados relacionais, arquivos, APIs, sistemas de ERP ou até sensores IoT. A extração de dados envolve desafios, especialmente quando se trata de lidar com diferentes formatos e estruturas de dados. Ferramentas de ETL são projetadas para automatizar esse processo, garantindo que os dados corretos sejam coletados sem sobrecarregar os sistemas de origem.
- Transformação: Depois de extraídos, os dados passam por uma série de transformações. Essa etapa pode incluir limpeza de dados, deduplicação, agregação, conversões de tipos de dados e aplicação de regras de negócio. A transformação garante que os dados estejam prontos para serem usados em análises, relatórios e outros sistemas.
- Carga: A última etapa é a carga, onde os dados transformados são movidos para o sistema de destino. Dependendo da arquitetura, isso pode ser um Data Warehouse, um Data Lake ou até uma solução de análise em tempo real. A eficiência dessa etapa depende muito da plataforma de destino e das ferramentas usadas.
3. Ingestão de Dados no Contexto do ETL
A ingestão de dados tornou-se uma parte essencial do processo de ETL, especialmente em ambientes onde os dados são gerados em tempo real e em grandes volumes.
A ingestão pode ser realizada de duas maneiras principais:
- Em lote (batch): Dados são coletados em intervalos de tempo pré-definidos e processados em grandes volumes de uma só vez.
- Em tempo real (streaming): Dados são processados à medida que são gerados, permitindo decisões rápidas e respostas instantâneas a eventos.
A combinação de ingestão de dados e ETL permite um fluxo de trabalho robusto para organizações que precisam lidar com dados dinâmicos. Por exemplo, o uso de Apache Kafka para ingestão em tempo real complementa perfeitamente uma estratégia de ETL para Big Data.
4. Principais Dúvidas sobre ETL
- O que é ETL e por que ele é essencial? O ETL é um processo fundamental que ajuda as empresas a consolidar dados de múltiplas fontes e transformá-los em informações úteis para tomadas de decisão.
- ETL e ELT são a mesma coisa? Embora semelhantes, no ELT (Extract, Load, Transform) os dados são carregados antes da transformação, ao contrário do ETL. O ELT é amplamente utilizado em data lakes e em arquiteturas baseadas em nuvem.
- Qual a diferença entre ETL em tempo real e em lote? No processamento em tempo real, os dados são transformados e carregados à medida que são gerados, enquanto no processamento em lote, os dados são processados em intervalos definidos.
- Quais as melhores práticas para otimizar pipelines de ETL? Automatizar processos, usar ferramentas especializadas e garantir a qualidade dos dados são práticas essenciais para otimizar ETL.
5. Principais Ferramentas de ETL no Mercado
Ferramentas modernas de ETL ajudam a automatizar e otimizar o processo de integração de dados. Aqui estão as mais recomendadas segundo o Quadrante Mágico do Gartner:
- Informatica PowerCenter: Solução robusta para integração de dados, amplamente usada em grandes corporações.
- Talend: Plataforma open-source que oferece uma excelente relação custo-benefício para pequenas e médias empresas.
- Microsoft Azure Data Factory: Uma solução na nuvem que facilita a integração de dados em ambientes híbridos.
- Google Cloud Dataflow: Ideal para o processamento de dados em tempo real e lote em ambientes de nuvem.
- Databricks: Utiliza Apache Spark para processar dados em larga escala, oferecendo suporte a Delta Live Tables (DLT) para ingestão e transformação de dados em tempo real.
6. A Revolução do ETL com Apache Spark
O Apache Spark transformou o cenário de ETL, especialmente para Big Data. Diferente de sistemas tradicionais, o Spark é projetado para processamento distribuído, o que permite uma manipulação de dados extremamente rápida e eficiente.
O Spark permite que empresas processem dados tanto em tempo real quanto em batch, usando o mesmo mecanismo. Isso torna o Spark uma solução versátil para pipelines ETL modernos, onde volumes massivos de dados precisam ser processados em pouco tempo.
7. ETL na Era de Big Data
Com a crescente quantidade de dados gerados, o ETL tradicional precisou evoluir para lidar com os Vs do Big Data:
- Volume: A capacidade de lidar com enormes quantidades de dados.
- Variedade: A diversidade de fontes de dados (estruturados e não estruturados).
- Velocidade: A velocidade com que os dados são gerados e processados.
- Veracidade: Garantir a precisão e qualidade dos dados.
- Valor: Transformar dados em valor real para as organizações.
No contexto de Big Data, data lakes e data lakehouses têm se mostrado ferramentas poderosas para gerenciar dados em larga escala. Eles complementam o ETL tradicional, permitindo uma melhor organização e estruturação dos dados.
8. ETL em Processos de Tempo Real
A necessidade de decisões rápidas fez com que o ETL em tempo real se tornasse crucial. Ferramentas como Apache Kafka e AWS Glue são amplamente usadas para suportar fluxos de dados em tempo real. A Databricks também oferece soluções como Delta Live Tables (DLT), que facilitam a ingestão e transformação contínua de dados com baixa latência.
9. Ferramentas e Arquiteturas Modernas de ETL em Nuvem
As soluções de ETL em nuvem estão se tornando cada vez mais populares, devido à escalabilidade e flexibilidade que oferecem. As principais plataformas incluem:
- Microsoft Azure: Com Azure Data Factory, que integra fontes de dados e sistemas de destino de forma eficiente.
- Google Cloud: Com Dataflow, uma solução escalável para pipelines de dados em tempo real.
- Amazon Web Services (AWS): Com AWS Glue, uma ferramenta de automação de pipelines de ETL.
- Databricks: Oferecendo a arquitetura Medallion, que organiza dados em camadas (Bronze, Silver, Gold), permitindo melhor governança e qualidade de dados.
10. Conclusão
O ETL continua sendo uma peça-chave na integração de dados, especialmente em um mundo onde Big Data, tempo real e nuvem desempenham papéis essenciais. Para maximizar o valor dos dados, as empresas devem escolher as ferramentas certas e adaptar seus processos ETL às necessidades modernas.
Conheça mais artigos do nosso blog – Big Data: O que é, conceito e definição e Power Center Informatica – Ferramenta de ETL
https://en.wikipedia.org/wiki/Extract,_transform,_load

