
Tutorial usando Apache Nifi
Nesse artigo vamos mostrar de uma maneira simples como criar um data flow para fazer integração de dados. O Apache Nifi é um projeto Open Source de integração de dados, que integra diversas origens com diversos tipos de destinos, usando bancos de dados, Hadoop (HDFS), Kafka, Spark, entre outros.
Conheça mais sobre o Apache Nifi na página do Projeto : https://nifi.apache.org/
Preparando Ambiente do Apache Nifi
Antes de começar a trabalhar com a ferramenta, vamos preparar o ambiente criando os diretórios no Linux (as pastas onde será gravado os arquivos de output do NiFi), para isso vamos executar os comandos a seguir:
mkdir –p /HDF/data (Criar a estrutura de diretórios)
chmod 777 –R /HDF/data (Da permissão para leitura e gravação nos diretórios)

Iniciando o Tutorial do Apache Nifi
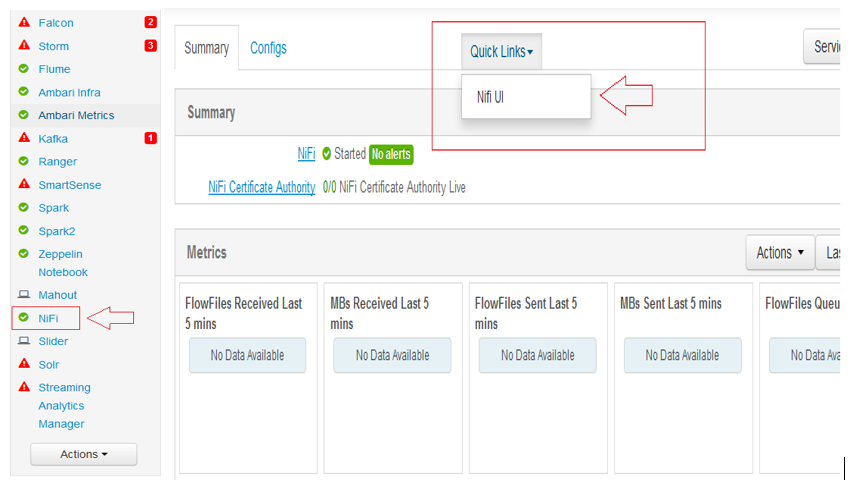
1ºPasso: Com NiFi já instalado no cluster, basta selecionar o NiFi no menu da esquerda e clicar em Quick Links e depois NiFi UI (Você vai ser redirecionado para interface web do NiFi)
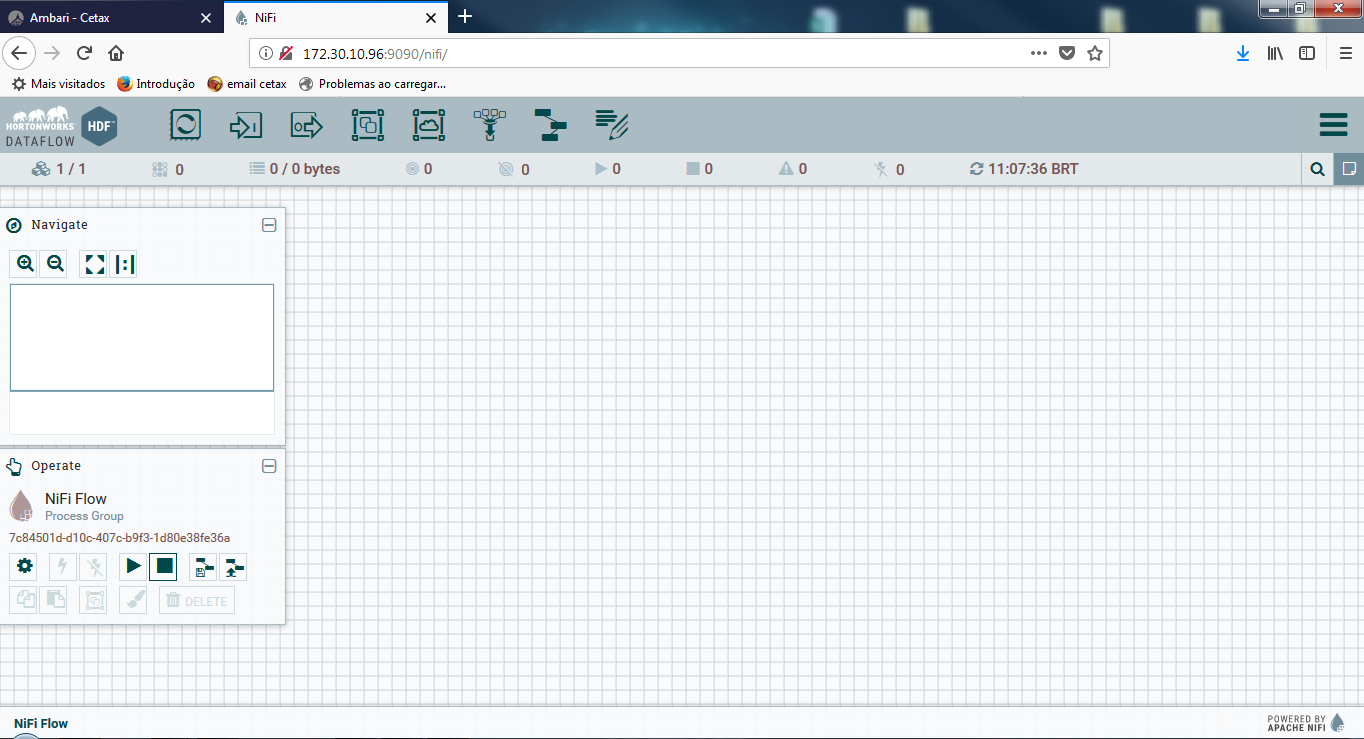
2ºPasso: Com a interface do NiFi aberta podemos come-çar a montar o DataFlow, neste DataFlow você vai coletar a saída de um app-log, dividir o conteúdo em múltiplos arqui- vos, compactar os arquivos e salvá-lo no diretório de destino com timestamp e nome do arquivo.
Adicionando e configurando Nifi Processor ‘TailFile’
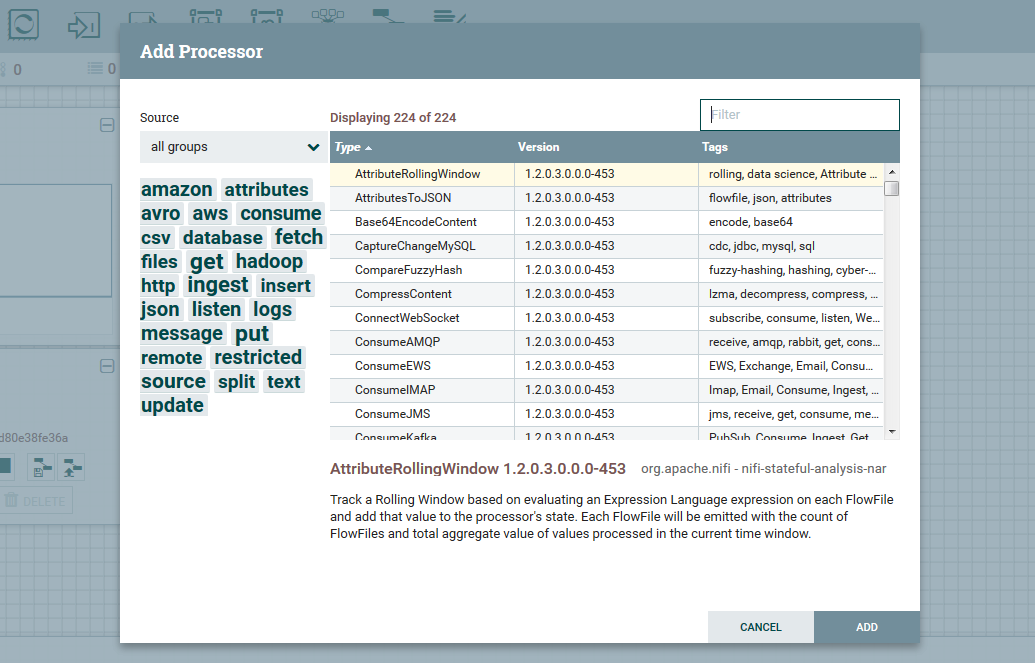
1ºPasso: Clique no botão de processor ( ) arraste e solte ao centro da tela principal, irá abrir uma janela como segue abaixo:
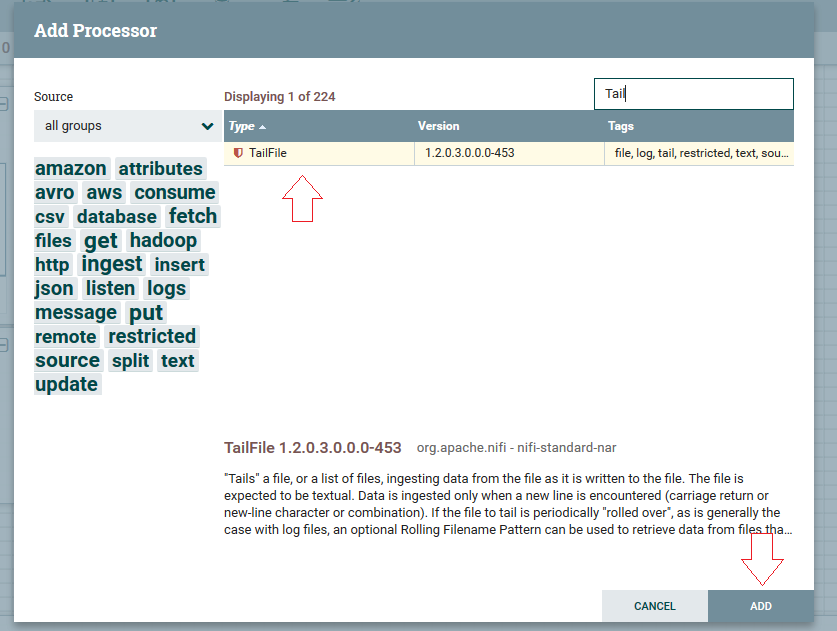
2ºPasso: No campo de pesquisa busque pelo Processor “TailFile”, selecione o processor e clique em “ADD”.
3ºPasso: Clique com botão direito no Processor que foi criado e vá em configure (configurações):
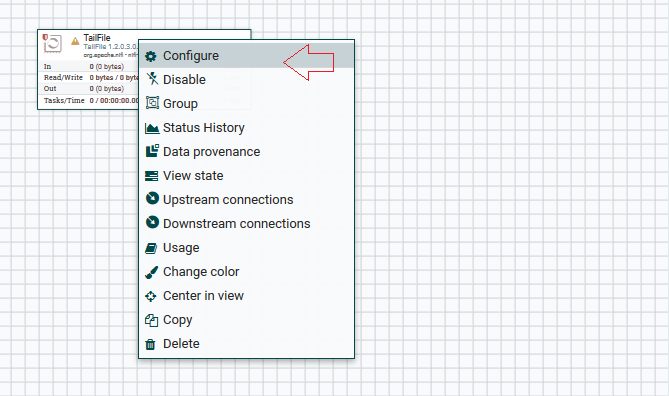
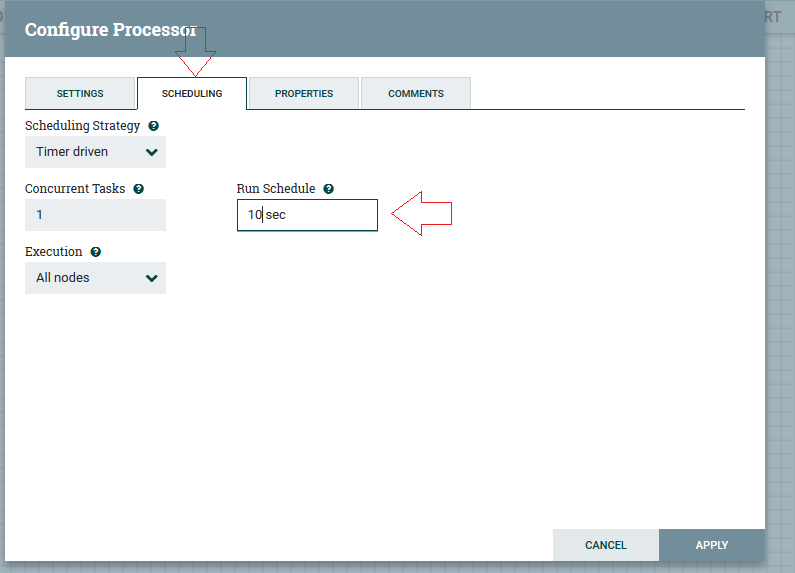
4ºPasso: Vamos agendar esta execução em 10 segundos, na aba “Scheduling”.
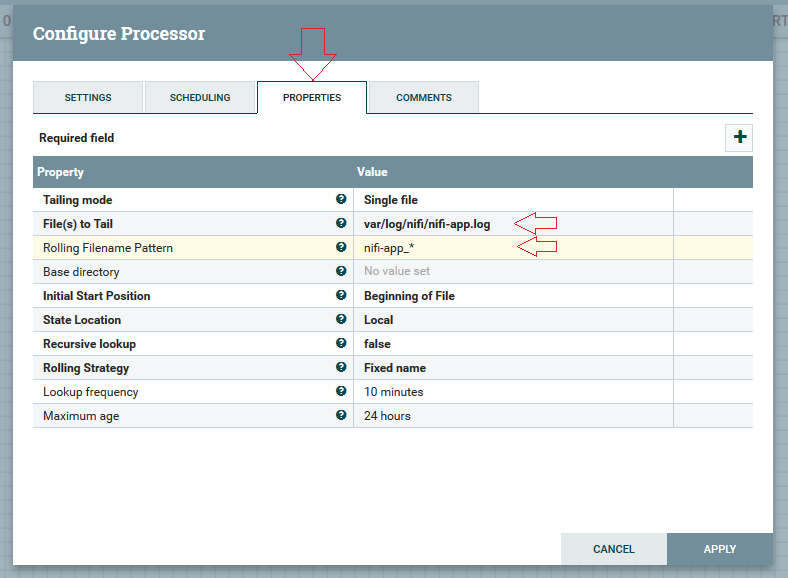
5ºPasso: Na aba “properties” devemos passar o caminho dos arquivos de log que irá extrair, neste caso é: “/var/log/nifi/nifi-app.log”. Na opção “Rolling Filename Pattern” o nome padrão dos arquivos, aqui irei utilizar “nifi-app_*” e clicar em “Apply”. OBS.: Este atributo é opcional, atributos em negrito é obrigatório o preenchimento.
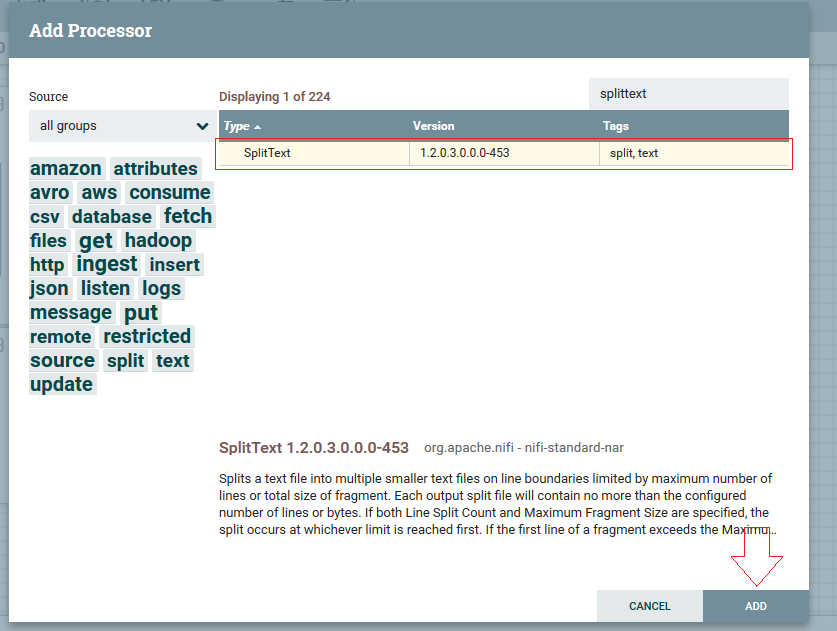
Adicionando e conectando ‘SplitText’ processor
1ºPasso: Com o “Tailfile” configurado, vamos arrastar mais um processor para o fluxo, clicando e arrastando com o botão ( ), mas agora utilizaremos outro processor: o “SplitText”.
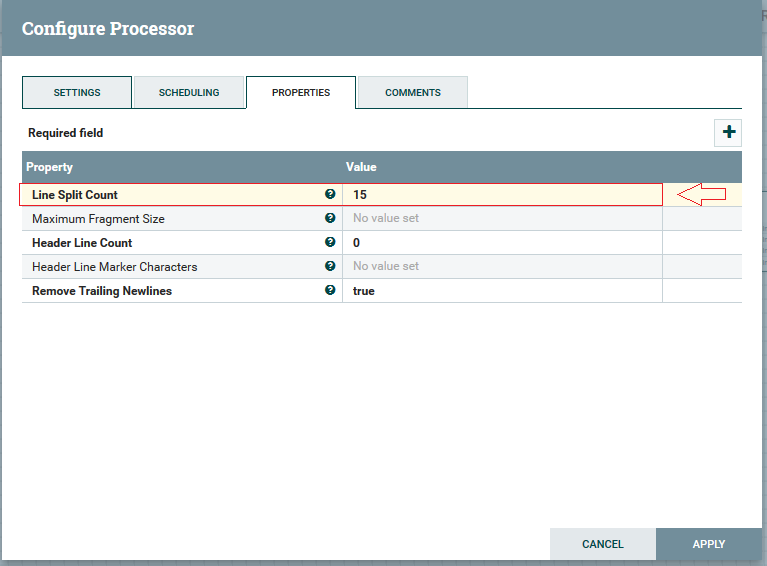
2ºPasso: Configurando “SplitText”, selecione o pro-cessor “SplitText” clique com botão direito e escolha a opção de configure. Colocaremos ao atributo “Line Split Count” o valor de 15, para extrair número máximo de 15 linhas do arquivo.
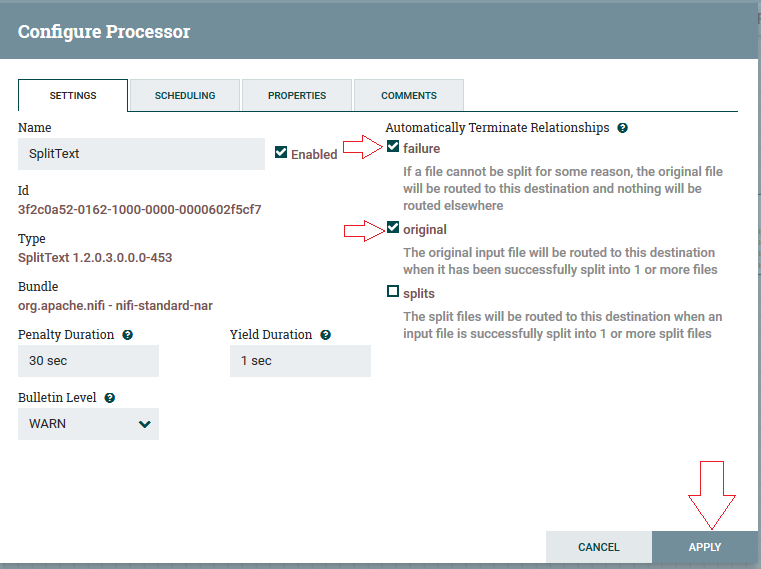
3ºPasso: Na aba settings, as checkbox “Failure” e “Original” devem ser marcadas, e após realizar clicar em “Apply”.
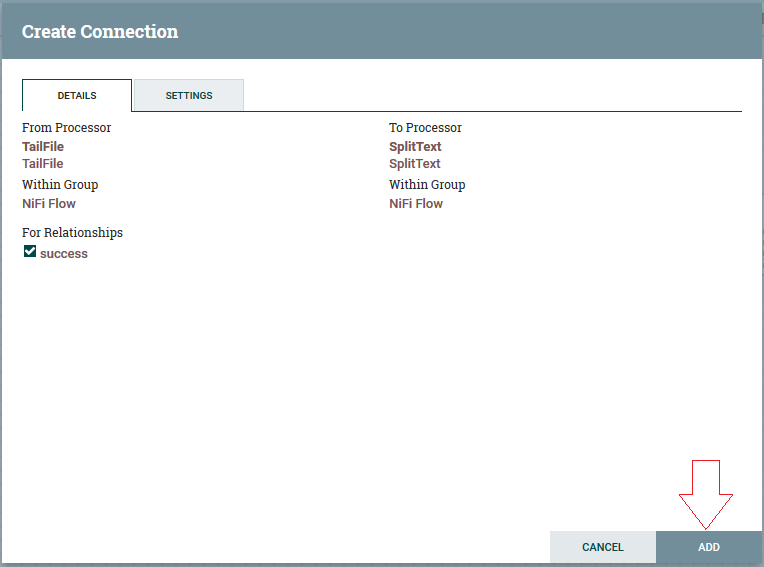
4ºPasso: Para realizar a conexão, devemos colocar o cursor do mouse em cima do processor “TailFile” até apare- cer uma flecha verde, segurar e arrastar até o processor de “SplitText”. Verificar se checkbox “sucess” está marcada e clicar em “ADD”:
Adicionando e conectando “CompressContent” processor
1ºPasso: Clicar e arrastar utilizando o botão (), neste passo recorreremos ao processor “CompressContent”
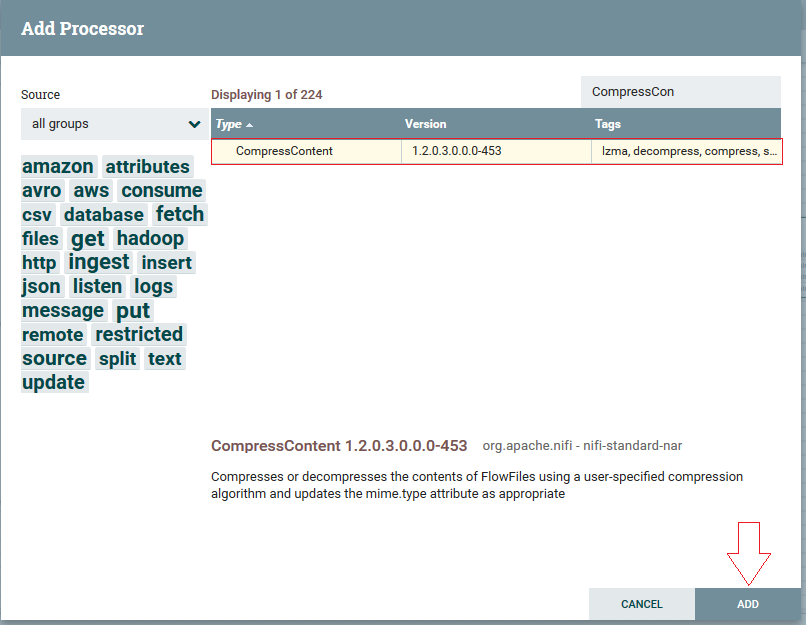
2ºPasso: Clicando com botão direito no processor criado, segue em “Configure”, na aba properties. Mudaremos o atributo “Compression Format” para “gzip”:
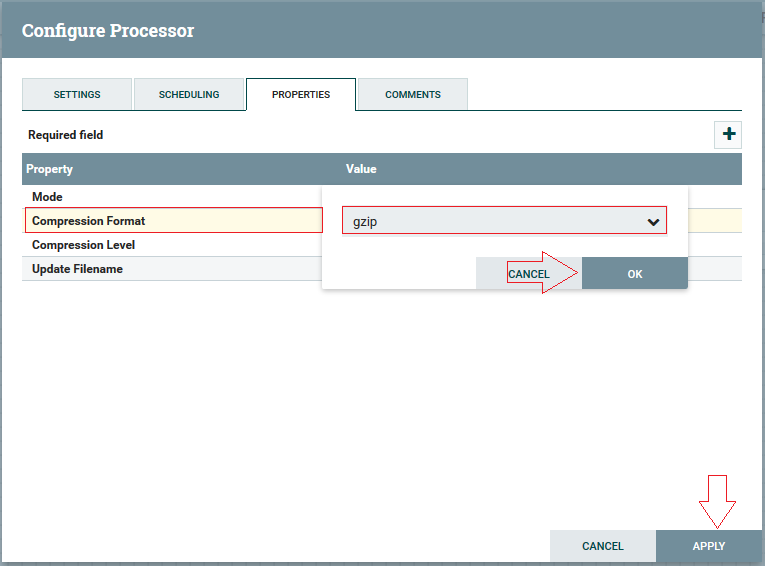
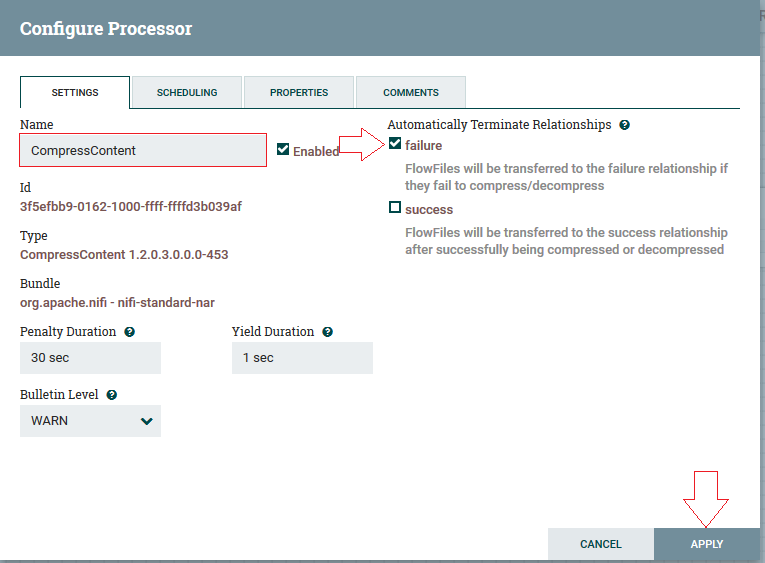
3ºPasso: Na aba “Settings”, devemos marcar o checkbox “Failure”, podendo alterar o nome do processor (opcional). E clicar em “Apply”
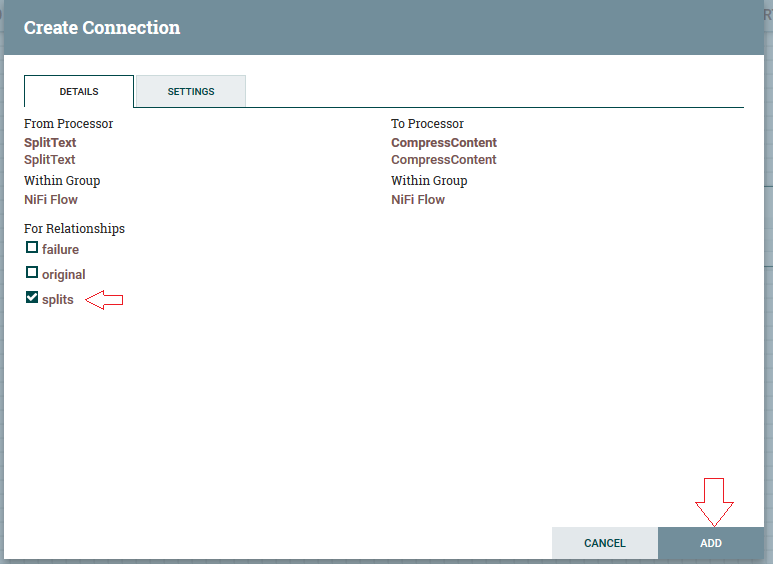
4ºPasso: Vamos realizar a conexão da mesma forma que no tópico anterior, posicionando o cursor do mouse em cima do processor “SplitText”, segurar a setinha verde, arrastando e soltando – a no processor “CompressContent”, que irá abrir as propriedades de conexão. Marque a checkbox “splits” e “ADD”:
Adicionando e conectando o “UpdateAttribute” processor
1ºPasso: Clicar e arrastar utilizando o botão (![]() ), neste passo recorreremos ao processor “UpdateAttribute”:
), neste passo recorreremos ao processor “UpdateAttribute”:
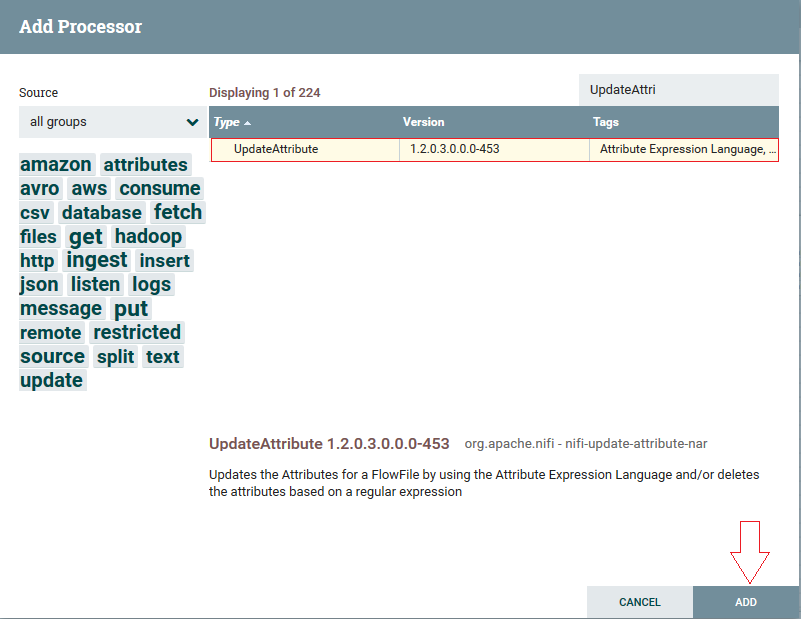
2º Passo: Clicar com botão o direito no processor criado, ir em configure, na aba Settings clicar no botão ( ) para adicionar um atributo novo, renomear para filename e clicar em “OK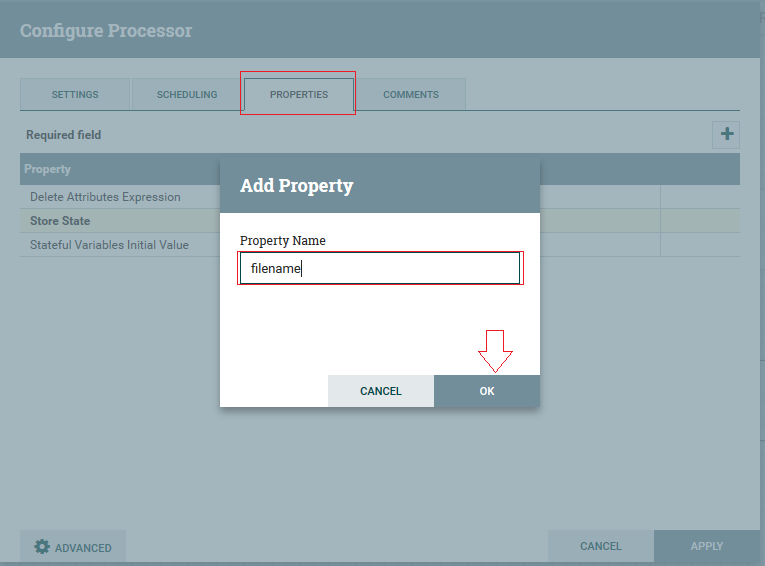 ”:
”:
3ºPasso: Os valores do atributo que iremos colocar é: “nifi-applog.${now():format(‘HH:mm:ss’)}.gz”, que irá anexar um prefixo ‘nifi-applog’ seguido de tempo no formato hora: minuto: segundo, com a extensão do arquivo em .gz (Nifi aceita linguagens de expressão):
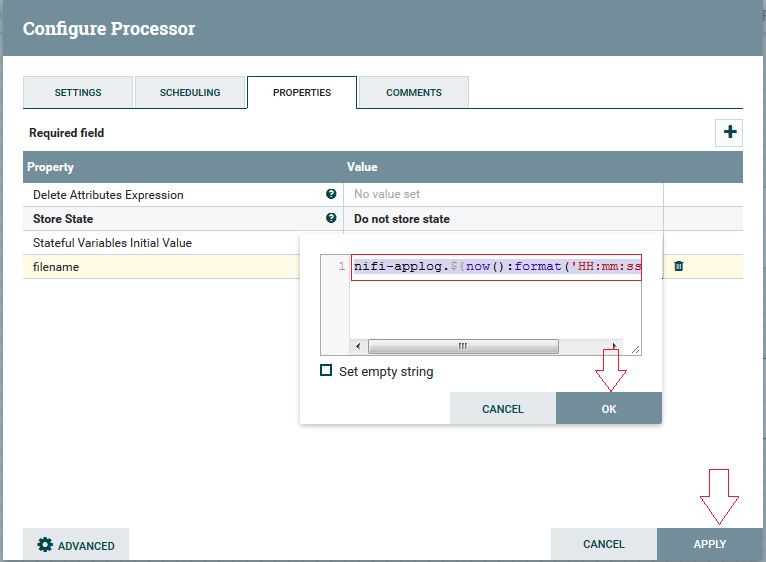
4º Passo: Realize a conexão do processor “Compress Content” para “UpdateAttribute” (Similar aos passos anteriores), marque a checkbox “sucess” e clique em “ADD”:
Adicionando e conectando “PutFile” processor
1ºPasso: Clicar e arrastar utilizando o botão (![]() ), neste passo recorreremos ao processor “PutFile”:
), neste passo recorreremos ao processor “PutFile”:
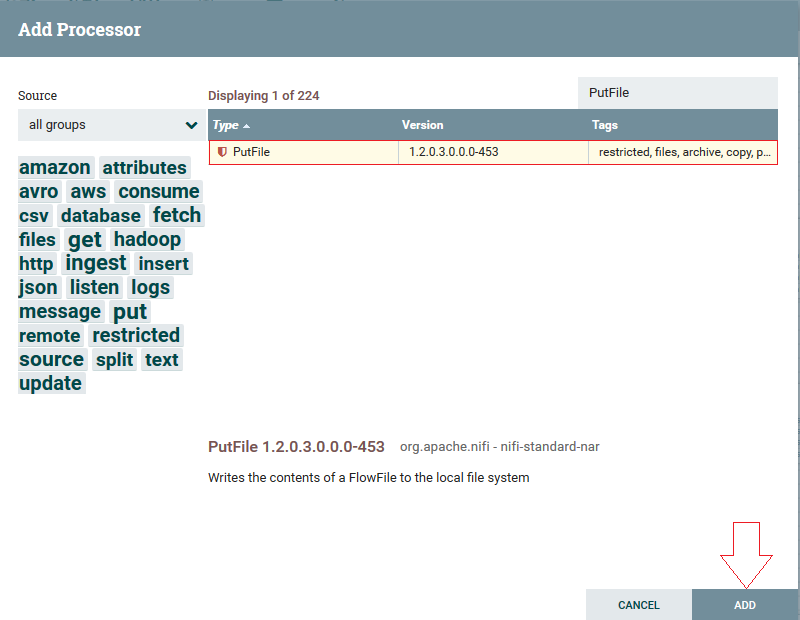
2º Passo: Clicando com botão direito na opção configure, na aba Properties, iremos configurar o atributo “Directory” (é o diretório onde os arquivos vão ser gravados):
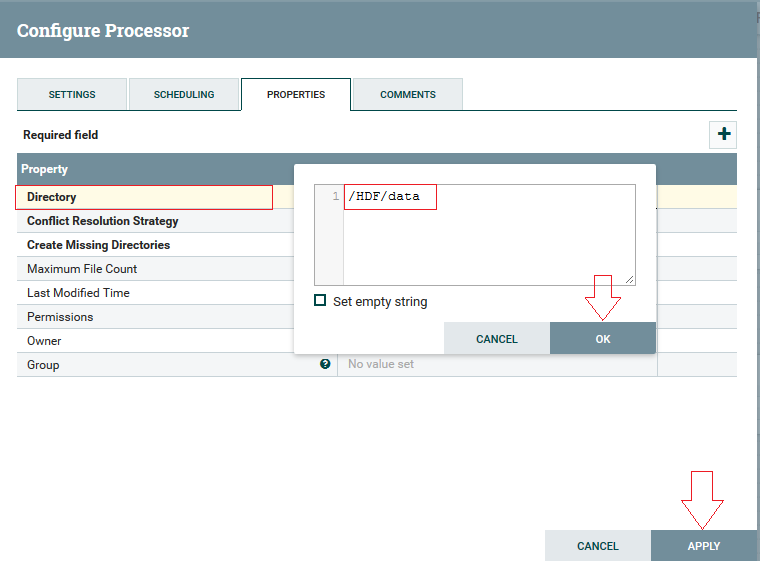
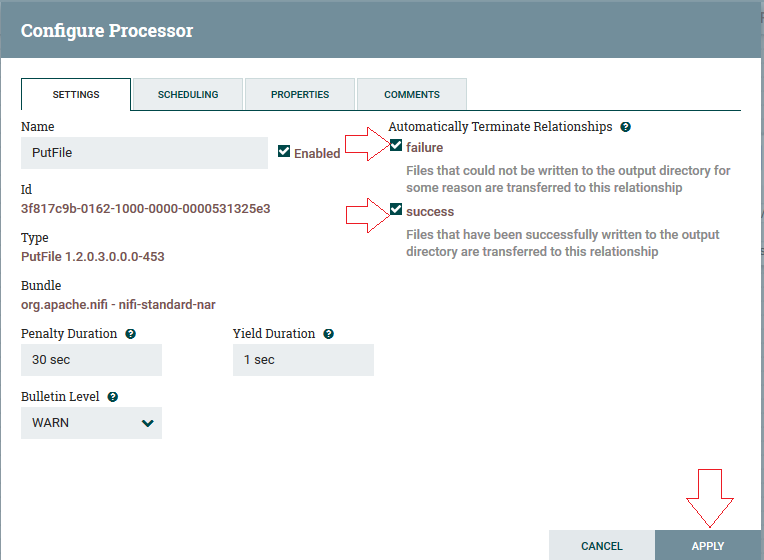
3º Passo: Na aba Settings deve-se marcar o checkbox “Sucess” e “Failure”, para encerrar automaticamente os relacionamentos e clique em Apply:
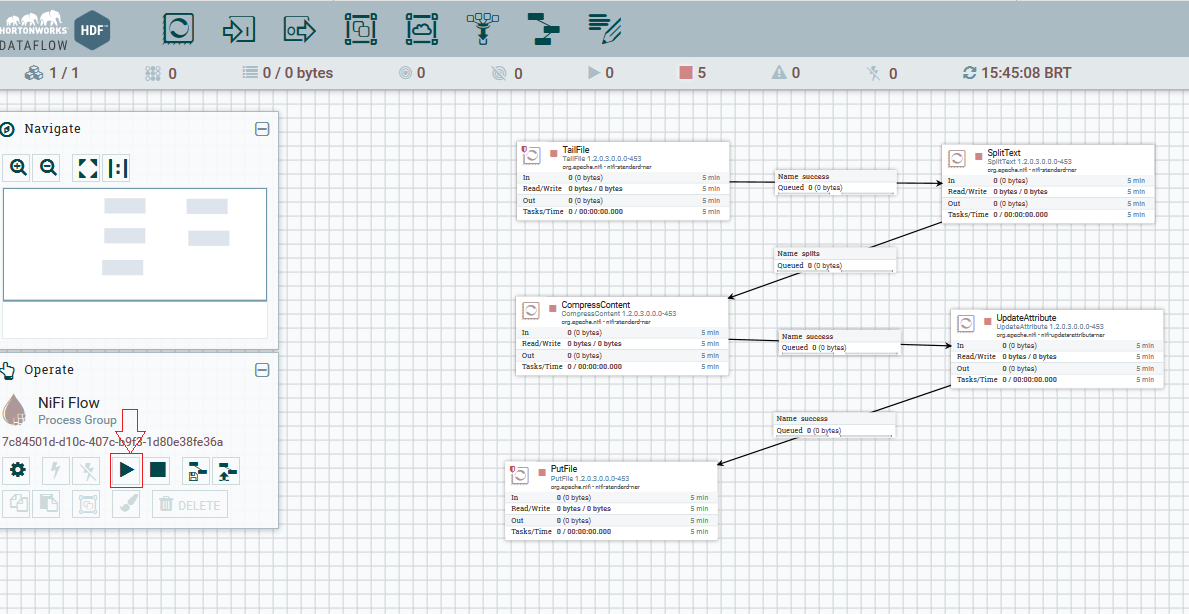
Executando o DataFlow
Clique fora de todos os processor, (não pode ter nenhum processor selecionado), na aba operate, clicar em play e aguardar a execução de todo fluxo, e em seguida clicar em stop (ou quando quiser parar o fluxo):
E para verificar o se arquivo foi gravado, basta entrar no diretório que foi definido no atributo “PutFile” e listar com o comando do Linux “ls”.
Conheçam mais sobre essa poderosa ferramenta de integração, nos produtos Hortonworks ele é o software principal do HDF ( Hortonworks Data Flow ) – https://br.hortonworks.com/products/data-platforms/hdf/
Também conheça a página original dele no https://nifi.apache.org
Apostamos muito nele como uma plataforma de integração de dados, que podem ser de quaisquer formatos de origem como Bancos de Dados (SQL), arquivos ( txt, csv, xml, json ), filas ( Kafka, Rabbit, MQ ), leitura em file system hadoop (HDFS) e processamento dos dados e destinos para todos os citados anteriormente.
Com um ambiente visual, simplifica o desenvolvimento das rotinas, onde também é possível fazer teste e debug online, analisando os dados no nível mais granular, acessando registro a registro.
O Apache Nifi possui excelente mecanismos de Rastreabilidade de dados e Logs para todas as etapas do fluxo de dados, isso dá uma enorme capacidade de análise sobre o “Tracking” de todas as informações que passam por ele.
Conheça mais sobre nossos treinamentos em https://www.cetax.com.br/cursos-de-business-intelligence-bi/
Visite também nossa página de materiais : https://www.cetax.com.br/materiais-de-bi-para-download/

